AI coding assistants have gone from "nice to have" to "default tooling" in less than two years. In 2024–2025, we've seen improvements of open-weight coding models, systems whose weights you can download, inspect, and run locally under permissive licences like Apache-2.0, MIT, or similar variants.
This article is a practical guide to the current best open-weight coding models in 2025. We focus on a curated top five that consistently perform at the very top on modern coding benchmarks like SWE-Bench Verified, LiveCodeBench, and Terminal-Bench 2.0.
We'll look at how each model performs on real-world bug-fixing and algorithmic coding, how heavy it is to run (VRAM, latency, scalability), licencing constraints you should actually care about, and when it makes sense to pick one model over the others.
If you want an easy way to run these locally, you can also try Kolosal AI, which has GLM-4.6, Kimi K2, Qwen3 Coder and other community favourites available as one-click local or BYO-cloud deployments.
The 5 Candidates We'll Focus On
For this analysis, we zoom in on five open-weights, self-hostable models that are both extremely strong at coding and realistic to deploy if you have decent hardware:
DeepSeek-V3.2-Exp — Experimental Mixture-of-Experts variant that currently sits at or near the top of LiveCodeBench and competes with the very best open models on SWE-Bench Verified.
Kimi K2 (Instruct / Thinking) — Massive MoE "thinking" model (~32B active parameters) with outstanding performance on SWE-Bench Verified and SWE-Bench Multilingual, and strong LiveCodeBench scores. Licenced under a modified MIT licence that still allows commercial use.
Qwen3-Coder (30B & 480B) — Apache-2.0 MoE coders designed for long-context, tool-using workflows. The 480B-A35B variant is one of the strongest open agentic coding models; the 30B-A3B variant is the more hardware-friendly option.
GLM-4.6 — Zhipu's latest GLM release, a reasoning-focused model with long context and strong agentic coding performance, including competitive Terminal-Bench 2.0 results when paired with modern agents.
MiniMax-M2 — A Mini model built for Max coding & agentic workflows.
These are the models that are currently sitting at the top of benchmarks in the current AI coding model leaderboards.
How We Chose These 5 Models
To keep this list useful (and not just a leaderboard dump), we looked at four main dimensions.
Modern Coding Benchmarks: We prioritised benchmarks that map to real developer tasks. SWE-Bench Verified tests end-to-end bug-fixing on real GitHub repos. LiveCodeBench offers continuously updated competitive-programming style problems sourced from LeetCode, Codeforces, AtCoder, ICPC, etc. Terminal-Bench 2.0 measures models controlling a real Linux terminal via an agent, compiling, running tests, editing files and configuring environments. Classic benchmarks like HumanEval and MBPP still appear in model cards, but by 2025 they're easy to overfit. We treat them as background sanity checks, not as tie-breakers.
Licence & Self-Hosting: We only considered models that ship downloadable weights and allow at least some form of commercial deployment under licences like Apache-2.0 (Qwen3-Coder, GPT-OSS family) or MIT/modified-MIT (DeepSeek models, Kimi K2, GLM family). Research-only models or strictly non-commercial licences are mentioned only as context, not as recommendations.
Hardware & Efficiency: Because this is a self-hosted article, we care a lot about whether the model can be reasonably run on a single 16–24 GB GPU (with 4-bit quantisation), a single 48 GB GPU, or if it basically needs a multi-GPU server. We also consider active parameters vs total parameters in MoE models, and latency/throughput for typical coding workflows.
Real-World Usability: Finally, we give extra weight to models that work well as IDE copilots, play nicely with repos + tools (Git, test runners, containerised environments), and already have good support in local orchestration tools (Kolosal AI, OpenHands, Ollama-style runners, etc.).
Quick Benchmark Overview
To keep this article grounded, we're anchoring our picks to three "modern" coding benchmarks plus a quick look at how heavy each model is to actually run.
LiveCodeBench v6 — Dynamic, competition-style coding tasks; hard to overfit because the dataset keeps moving. All of our top models are evaluated on v6.
SWE-Bench Verified — Real GitHub issues applied to real repos, where the model acts like a "patch bot" using tools (bash, editor), evaluated via the Terminus-style SWE-agent harness. Vendors now report "SWE-Bench Verified" as a primary repo-coding metric.
Terminal-Bench (Terminus-2) — Measures full terminal agents doing long-horizon tasks in a real shell (install deps, run tests, edit files). The official leaderboard (tbench.ai) runs a fixed Terminus agent on many models, so you can compare open vs proprietary fairly.
We also peek at secondary signals when they're clearly relevant: Artificial Analysis "Coding index" & AA LCB (aggregates LCB, SciCode, Terminal-Bench Hard, etc.) and CC-Bench / human-judged multi-turn coding.
What's the Strongest Model?
These are approximate ranges, not a formal leaderboard; they're meant to give you a sense of relative strength as of current benchmark.
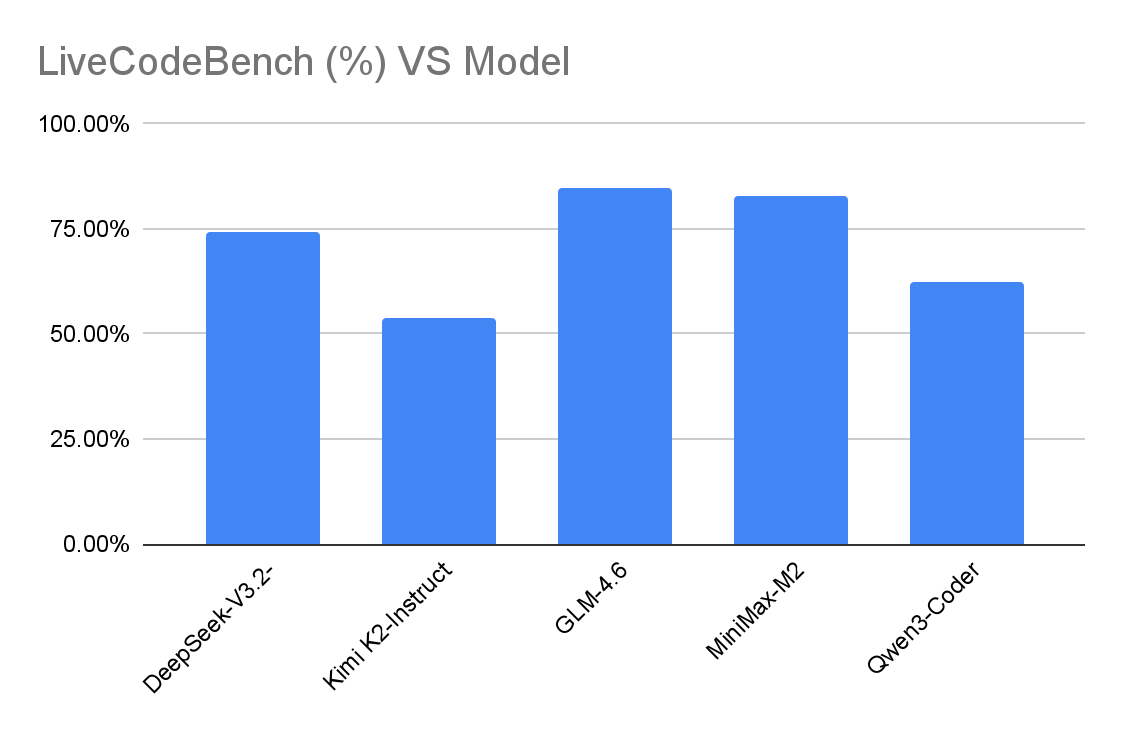
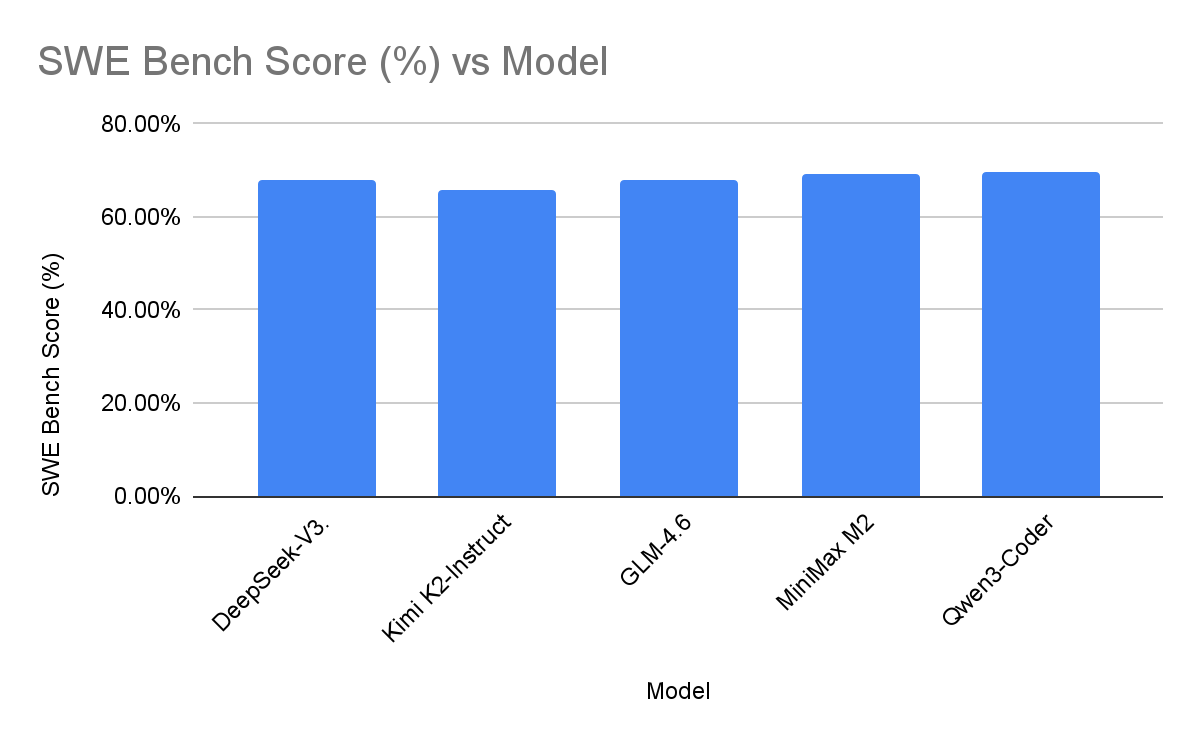
There isn't a single "final boss" here – the five models swap places depending on the benchmark. On LiveCodeBench v6, GLM-4.6 and MiniMax-M2 are clearly ahead (mid-80s / low-80s), with DeepSeek-V3.2-Exp a bit behind (mid-70s), then Qwen3-Coder (low-60s) and Kimi K2-Instruct (low-50s). On SWE-Bench Verified, all five sit in a tight band from mid-60s to just under 70% Resolved.
So: if you want leaderboard bragging, you can cherry-pick GLM-4.6 / MiniMax-M2 on LiveCodeBench or Qwen3-Coder / MiniMax-M2 on SWE-Bench. For real use, they're all top-tier; a 2-4 point gap on one benchmark matters less than licence, hardware, and whether you prioritise raw coding vs long-horizon tools/agents.
Takeaway: all five of our focus models sit in a very tight band (roughly mid-60s to just under 70% on SWE-Bench Verified). Qwen3-Coder-480B are fractionally on top; DeepSeek-V3.2-Exp and GLM-4.6 are essentially tied once you account for evaluation noise and harness differences.
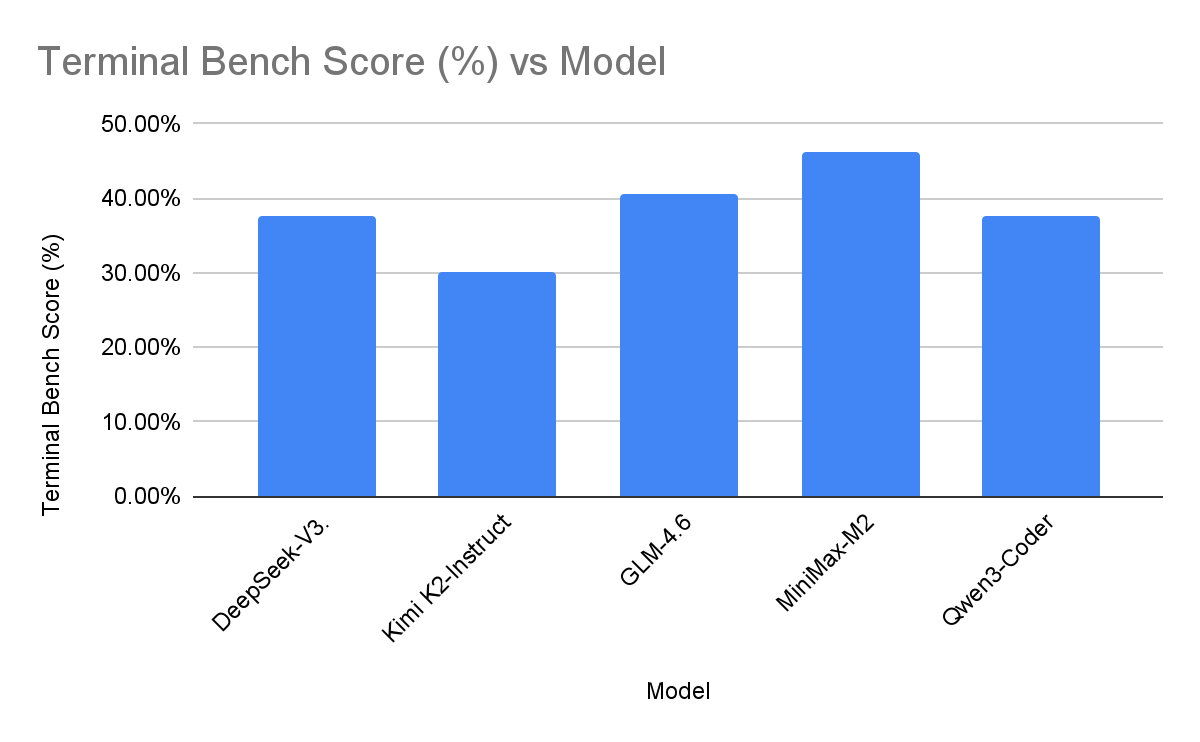
On Terminal-Bench 2.0, which measures real shell and tool use, MiniMax-M2 has the clearest edge in our data, with GLM-4.6 and Qwen3-Coder close behind, and DeepSeek-V3.2-Exp and Kimi K2 a few points lower. Again, the spread is only on the order of 5–10 percentage points – this is about fine-grained strengths, not "good vs bad" models.
Hardware and Context Requirements
All five models are open-weights and self-hostable, but they live at very different scales.
DeepSeek-V3.2-Exp: 671B-parameter MoE (256 experts), ~37B active per token. Context ~128K–160K tokens. Official deployment guides talk about 8× H200 / 16× H100-80GB for full-precision inference. You can quantize and shard to run on fewer GPUs, but this is still a data-center-scale model.
Kimi K2 (0711 / 0905): ~1T total params, 32B active via MoE (384 experts). Context originally 128K, bumped to 256K tokens in K2-0905 update. Similar order of magnitude to DeepSeek-V3.x – think multi-GPU boxes or modest clusters for comfortable latency, though 4-bit quantization plus tensor parallelism can bring it into the "enthusiast lab" range.
GLM-4.6: ~355B total, 32B active (MoE). Context 200K input, 128K max output tokens – one of the longest among open-weights models. Similar MoE footprint to K2, but Zhipu emphasizes token-efficiency improvements (~15% fewer tokens than 4.5 on CC-Bench scenarios).
These three are your "frontier-scale open" options: absurd context windows, SOTA coding, but realistically aimed at labs, clouds or serious on-prem clusters, not a single 24GB card.
Qwen3-Coder-480B vs 30B: The 480B-A35B is a huge MoE with ~35B active parameters; 256K context (extendable to 1M). This is the full SOTA coding model, but similar in deployment profile to K2/GLM. The Qwen3-Coder-30B-A3B is ~30.5B total, 3.3B active thanks to MoE; 256K context; achieves ~62.6% LCB – competitive with much larger dense models while being dramatically easier to host. The 30B MoE variant is a sweet spot for 1× 48GB / 2× 24GB enthusiast rigs at 4-bit quant.
MiniMax-M2: 230B-parameter sparse MoE with ~10B active parameters per token, explicitly tuned for coding and agentic workflows. Context up to ~200K–204K input tokens with around 128K–131K output capacity. Despite the small active size, this still needs roughly 80–130 GB VRAM even with 4-bit/FP8 quantisation. Recommended setups: 2× A100 80GB / 4× A100 40GB / 8× RTX 4090 with tensor or pipeline parallelism.
Conclusion
In summary, the best open-source coding models of 2025 form a tight top tier rather than a single winner. DeepSeek-V3.2-Exp is the strongest raw coder if you have serious cluster-class hardware, while Qwen3-Coder (30B & 480B) is the best overall choice thanks to its balance of benchmark strength, Apache-2.0 licence, and scalable sizes. Kimi K2 shines if you want a "thinking" MoE tuned for repos and terminals, and GLM-4.6 is ideal for bilingual (Chinese–English) and ultra-long-context coding. Choosing any of these five gives you a frontier-level coding assistant you can actually run under your own control.
Running These Coding Models Locally with Kolosal AI
If you don't want to spend hours wiring up inference servers and agents, you can offload that part to tools like Kolosal AI.
Kolosal AI is an open-source desktop platform for running local and self-hosted models. Instead of manually setting up vLLM, text-generation-webui, or custom Docker stacks, you can browse and download popular open-weights like GLM-4.6, Qwen3-Coder, Kimi K2, and MiniMax-M2. Run them locally on your own GPUs or connect to your BYO-cloud instances. Expose a simple HTTP endpoint that your editor, terminal agent, or internal tools can call.
For this top-5 list, that means you can prototype with Qwen3-Coder-30B or MiniMax on a single powerful workstation, experiment with GLM-4.6 or Kimi K2 as repo-scale coding copilots, and later swap in DeepSeek-V3.2-Exp or Qwen3-Coder-480B without rewriting your whole stack.